仙台で3Dゲームクライアント開発を行っております、にしきんです。
メッシュの描画発行も例によってPS4世代から活発に動いたトピックだと思います。GPU駆動なMDIが有名でしょうか。現在では、カオス化したジオメトリパイプラインを再定義するメッシュシェーダーというものまで登場しました。
ここまでの話だけでUnityのMeshRendererが処理時間的に遅い理由は十分に説明できて、単一の描画対象の情報のみをバインドする、「レガシーな」とでもいうべきDrawCallと対応しているからです。個人的には、できればMeshRendererは使いたくないです。
とはいえ、おそらくUnityはMDIやMeshShaderが利用できない状況だと思います。(MDIについてはそれっぽいAPIがあったんですが、マッピングされている確証が得られませんでした。)
代わりと言ってはなんですが、Unity 2022.1から正式的にBatchRendererGroup(BRG)というものが提供されました。これはUnity独自のDrawCall発行APIです。折角なので、このBRGを使ってMeshRendererを卒業してみましょう。
BRGの詳細
BRGがUnity独自であるとはいえ、中で何をやってるのかはGPU側で必要な対処等から大体わかるのですが、結局はCPU側からの命令でハードウェアインスタンシングを使って描画を発行する仕組みです。
通常のDrawMeshInstancedのようなインスタンシングを利用する際との大きな違いとして、ユーザー側でSSBO(一部環境ではUBOにフォールバックされる)にインスタンスの情報を詰めておくことが必要となります。各オブジェクト描画時には各シェーダでSV_InstanceIDをもとに描画対象の情報にアクセスする必要がある訳ですが、Unity側でそのSSBOの位置へのアドレス情報となるようなUBOを、SSBOと一緒にバインドしてくれるのです。
文言にするとちょっと回りくどい感じですが、とにかくBRGはコアの指針として、SSBOにインスタンス情報を詰めたいということですね。まあ通例SSBOはアクセスが若干遅いと思うので、描画自体のパフォーマンスのリグレッションはほかの手法と比べてありそうな気はしますが、それはそれとして一般的な手法だと思います。
また、BRGを使う場合は、実際に何についてどのように描画を発行するかについてが、ユーザー側実装として開放されています。つまり、カリングやインスタンシングの成立のさせ方がこちらの責任になるということです。特にカリングはMeshRendererを使っている場合ネックに感じていた方は多いと思いますので、最高ですね。BRGではこのあたり、ユーザー側が頑張れば高速化できるようになるという事です。
実装の流れ
大まかに以下のような実装が必要となります。
・シェーダに対応したSSBO(フォールバックが必要な場合はUBO)を作成する。
・描画物について、シェーダで参照する必要がある情報が変わった時にはSSBOを更新し、描画パイプライン上の適当なタイミングでGPUにアップロードする。
・BRGの描画発行APIをつかって、カリングを行いながら描画発行を行う
・(特に独自SRPの場合)シェーダー側で適切なインスタンス情報参照をUBO、SSBOから行えるようにする。
BRGのAPIはそこまで詳しくドキュメントがあるわけでもないので、ハイパフォーマンスに作るのは人によっては大変かもしれません。クライアント側で簡単に扱えるようにしつつのバッファの管理なども、実際にやってみるとそれ相応に面倒です。美しい設計を目指して自由にやってみてください。
実装結果
ということで実装結果です。
約3000ほどの、大量のUnityプリミティブなオブジェクトが描画されていますが、BRGを使った描画のためヒエラルキーに対応するGameObjectがまったく存在しません。
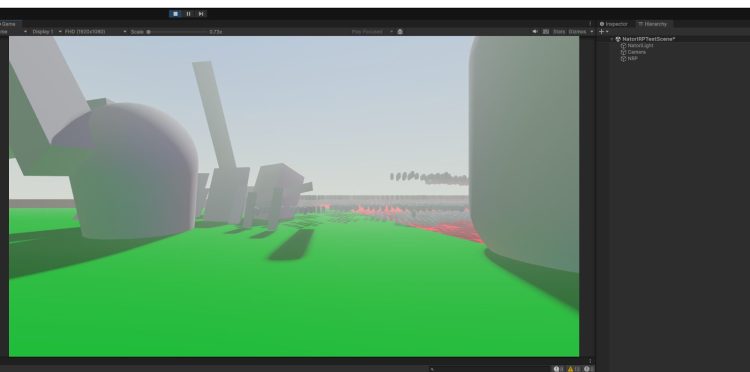
以下が同じシーンをMeshRendererで描画したときのヒエラルキー構成です。
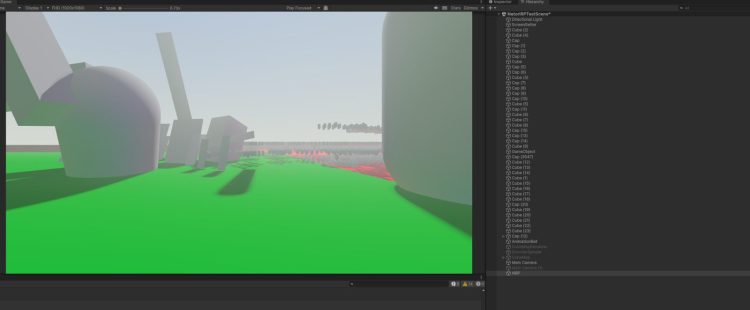
次にパフォーマンスについてです。エディター上でのCPU(Intel i9 13900k)パフォーマンスについてですが、今回の適当な約3000オブジェクトで構成されるシーンの描画について、BRGでは以下の画像のように描画パイプライン全体のメインスレッドが約0.6ms、レンダースレッドが約0.3msそれぞれ処理に使用されました。
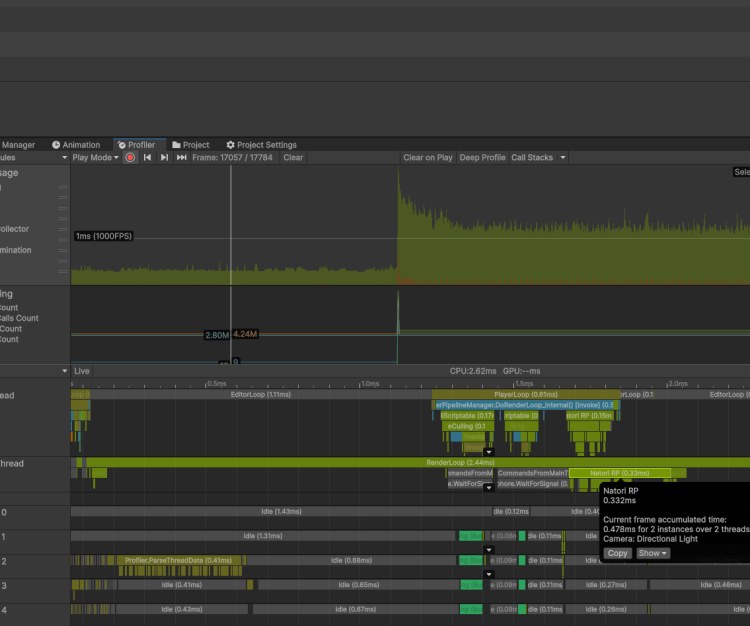
通常のMeshRendererで該当のシーンを描画した際は、以下の画像のようにメインスレッドが約1.7ms、レンダースレッドが約1.1msほど処理に使用されております。
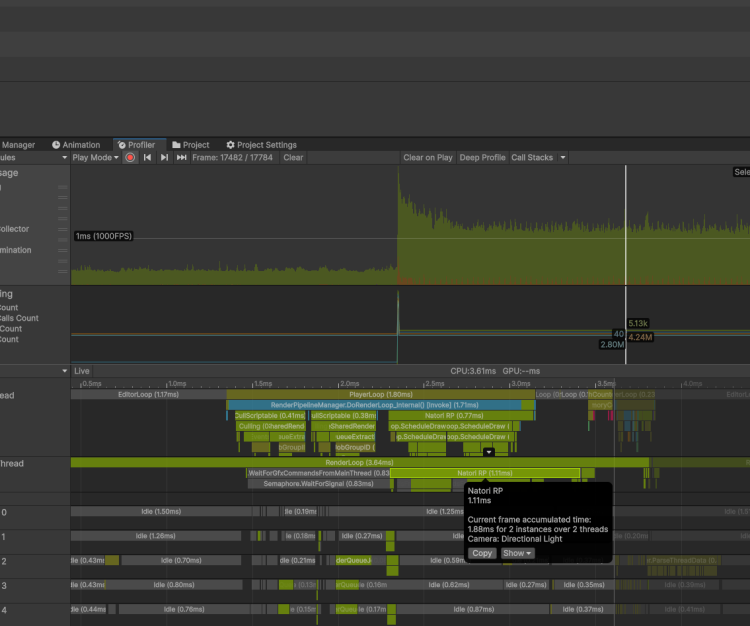
描画発行自体でなくパイプライン全体の時間で計測してもトリプルスコアのような差が出ましたが、BRGの方が短い時間で処理が済むという傾向は、オブジェクトが増えれば増えるほど強調されます。(今回の3000は現実としてはオブジェクトが少なめのシーンだと言えるかなと思います。)IL2CPPで確認すれば、双方もう少し短くなるはずです。
ちなみにGPU側のパフォーマンスについてですが、今回は時間の関係でビルドしてPIXでの確認を行えていません。どの程度インスタンシングできるシーンかにも依存しますが、基本的には速くなるような傾向がみられるものだったと思います。後で時間があれば追記したいと思います。
余談
BRGの実装はパフォーマンスが高速ですね、で基本的に話は終わりなのですが一つだけ強調しておきたいポイントがあります。
上記スクショの中で、ヒエラルキーに何もないのに描画が成立していましたよね。そこでもしれっと記述していましたが、BRGではGameObjectにたよらない描画が可能です。
……って、もしかして良い話に聞こえませんでしたかね。もちろん、以下のように一応旧来のワークフロー互換性を目指してGameObjectとあえて一緒に使う事も可能ではあります。
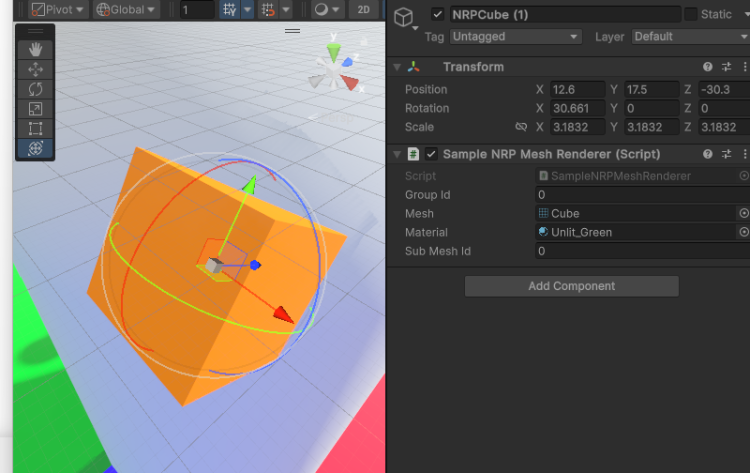
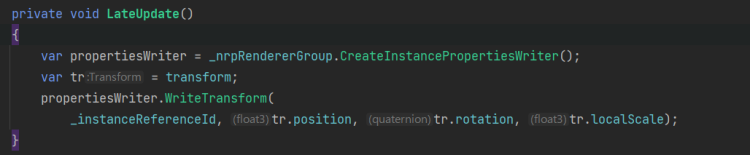
ただ、BRGを使う場合はGameObjectを使わずに済むことにいろいろな想いを馳せることになるんじゃないかなと思います。様々な歴史的オーバーヘッドを破壊し、自分だけのピュアな描画物体をUnity上で作れるようになったことで、文明開化の音が聞こえてくるかもしれません。
ところで、鋭い方はBRGではSkinnedMeshRendererをどうするんだという疑問を抱かれるでしょうか。単純なメッシュの描画システムですからね。ですがご安心を。アニメーションやスキニングを完全に自作することでAnimator・SkinnedMeshRenderer相当の実装の置き換えが可能です!(検証済み。これについてもいずれ記事を出すと思います。)
まあ、完全に自作すればそりゃあなんでもあるに決まってるでしょうという感じなんですが、置き換えの際は適切に実装することで、Unityビルトインのソリューションよりも、アニメーション及びスキニング両方についてパフォーマンスの向上が見込めます。また、AnimatorやPlayableGraphに縛られない形で自分たちでアニメーションワークフローを作成できることは、一部の人が感涙に咽ぶんじゃないかなと思います。
このような基盤的要素の作成が、エンジン上でパフォーマンスに良い形で自由になってることは、最近のUnityにおいて、一番すばらしい進歩だと個人的には思っています。
最後に
ILでは3Dゲーム開発にも取り組んでおります。興味がある方は是非採用情報をご確認ください。

