宮城県仙台市の3Dゲームエンジニア、にしきんです。
前回、AnimatorやPlayableGraphからも卒業!?スキニング・スケルタルアニメーションの独自実装をして全局面で勝つ・前編という記事を公開しました。後編をお見せする前に、具体的なトピックでGPU向けの処理を書く話を挟むことにします。
前編でスキニングのGPU処理時間は10%ほどの改善に留まっており、パフォーマンス改善の主な部分はJob/BurstによるCPU部分についてでした。実際、私が挙げていた問題は殆どすべてがAnimatorに絡む部分でしたから、これは主にCPUなトピックです。
しかし、恐らく普段仕事でUnityを使っているアベレージな人が取り組もうとして難しいのは、公式のスキニングシェーダと同等のパフォーマンスな独自スキニングシェーダを用意すること(GPU処理を書くこと)でしょう。Unity公式のシェーダを丸写しすればともかく、慣れていない人にとっては難題なはずです。まあ僕も初心者みたいなものですが。
ということで、GPU処理の実装がどのように進むのか簡単な思考プロセスのようなものをお見せする意図で、前編で用意した独自アニメーションシステムの上に、BlendShapeを実装する話をしていきます。私の書く記事としてはいつものことですが、ザックリした記事です。読めば同水準の実装が直ちに自分たちでできるようになるということは想定してないです。気楽に、斜めに読んでください。
前編でお見せしていたパフォーマンス検証では、ペンギンがスケルタルアニメーションで動いていただけなのでBlendShapeは走っておらず、計測に含まれておりませんでした。ネタバレですが、今回お見せする実装はUnity 2023.2b2でのSkinnedMeshRendererと比べてGPU上ほぼ倍速です。Unity 2023では、前編でも触れましたが公式にSkinning、BlendShape両方にGPUパフォーマンス改善が入っておりましたから、そこに対して更に倍速を出せるというのはきっと素晴らしい事ですね。
Unity2023のBlendShape公式処理、その問題
公式のBlendShapeシェーダを読んでみましょう。Archiveからダウンロードすることが出来ます。
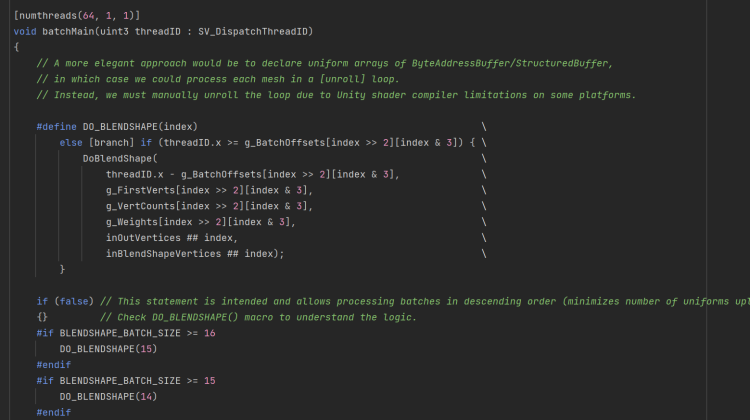
公式シェーダの中身を見ると8つのメッシュについて1Dispatchで同時にBlendShape処理を適用していることが分かりますが、この1Dispatchの中でそれぞれのメッシュで取り扱うBlendShapeは一つだけであることにも気が付きます。つまり、複数BlendShapeがあるメッシュに対して有効だった場合は、その有効な数分Dispatchが追加されます。Dispatchのそれぞれで、SSBOからの読み出しとSSBOへの書き込みを繰り返します。
例えばキャラクターの表情は複数のBlendShapeを合成して表現されることがありますが、そのようなメッシュが混ざっているケースで、Unityの戦略は非効率になりがちだということです。(同時に一つだけのBlendShapeのみが利用されるなら最適な実装です。)
特にBlendShapeはただでさえ高速な計算部分が、単に僅かな積と和ですから、あまりいい気配がしないのですね。
戦略
前述した問題を解決するためには同時に発動する数分のBlendShapeを一挙に適応してしまえばよさそうです。しかし、「任意数とそのWeight」を取得するためにアクセスのためのレイテンシが大きいバッファを使うと本末転倒な気がします。まあサイズは小さいバッファになるでしょうから、L2のような場所には乗り続けるでしょうか。BlendShapeが多く同時に使われるシナリオが支配的なら試してみて良いかもしれません。
私のケースでは今回、2つ以上のBlendShapeがあるメッシュに同時適応されるシチュエーションで堅実にUnityの実装にパフォーマンス上勝てればよいかなと判断しておりましたので、定数を利用し、8つのメッシュについてそれぞれ4つまでのBlendShapeを同時に取り扱う情報を持たせるようにしました。つまり、一回頂点情報を読み出して書き込むまでの間に、4つまでのBlendShapeを適用できるようにするということです。それ以上の数がある場合はDispatchを分割します。
この時、8体メッシュをそれぞれ4つのBlendShapeについてまとめて処理する為に必要な定数の合計サイズは192byteでした。複数Dispatch分をまとめてアップしますが、アラインメントに注意します。
実行結果
戦略を踏まえ、早速実装結果に入ります。
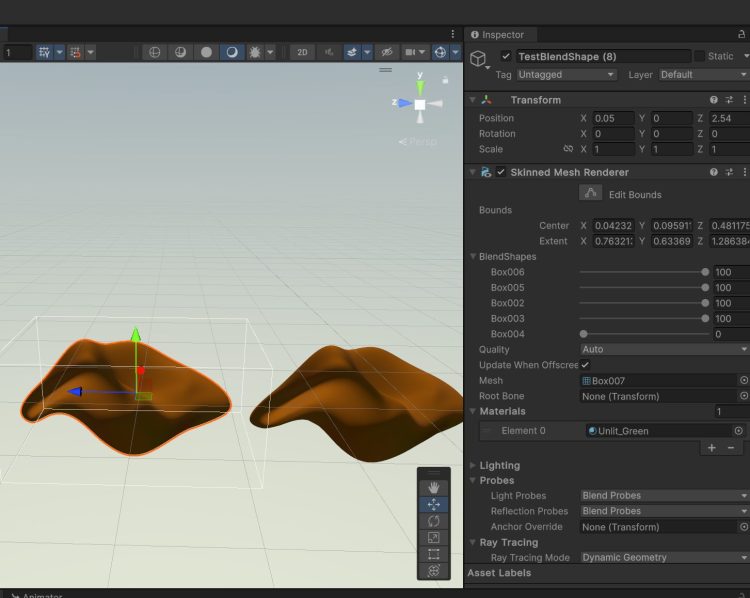
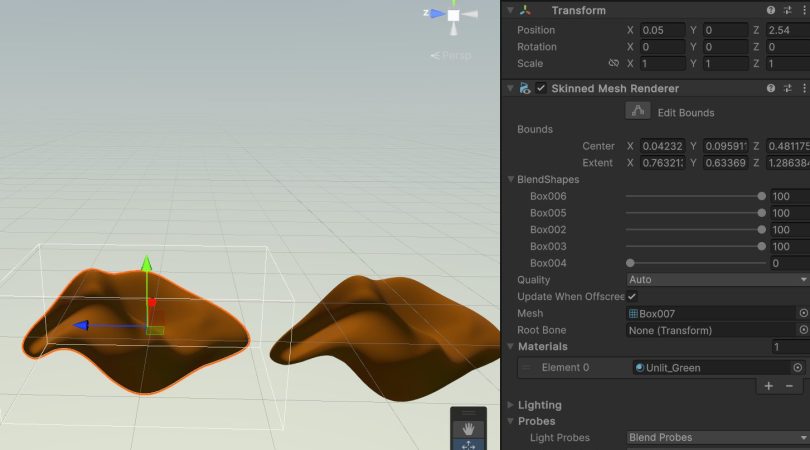
まず見た目の確認ですが、色々BlendShapeを有効にしてみて、上図のように同じ風に見えたのでまあよいでしょう。(適当)
続いて本題のパフォーマンスの検証です。与えた最適化から
- 4つのBlendShape適応時の計算時間
- 1つのBlendShape適応時の計算時間
についてそれぞれUnityのSkinnedMeshRendererと独自手法とを比較します。4つのBlendShapeが有効な時は独自手法で計算時間が短くなり、1つのBlendShapeが有効な時の計算時間は両手法大体同じくらいの計算時間になるような結果が期待できるはずです。
パフォーマンスは、上のスクリーンショットにも映っている頂点数約6500の謎BlendShape検証用モデルを利用して確認します。グラフィクスAPIはDX12、ビルドはDevelopment BuildでMasterです。ハードウェアは厳しめの性能環境としてIntel UHD 770(13900k)を利用します。尚、今回はGPUの処理時間にフォーカスしているので、PIXでのみ結果を確認していきます。
また、計算時間が見えやすくなるように、メッシュは同時に8つ描画してみます。(これは1Dispatchで処理できるメッシュのバッチ単位でもありますね。)
4つのBlendShapeが有効な時の計算時間
それではまず4つのBlendShapeを有効にしたケースを見てみましょう。
UnityのSkinnedMeshRendererでは以下の画像のように合計で584msほど掛かりました。説明したとおり、Dispatchが分割されているのが確認できます。
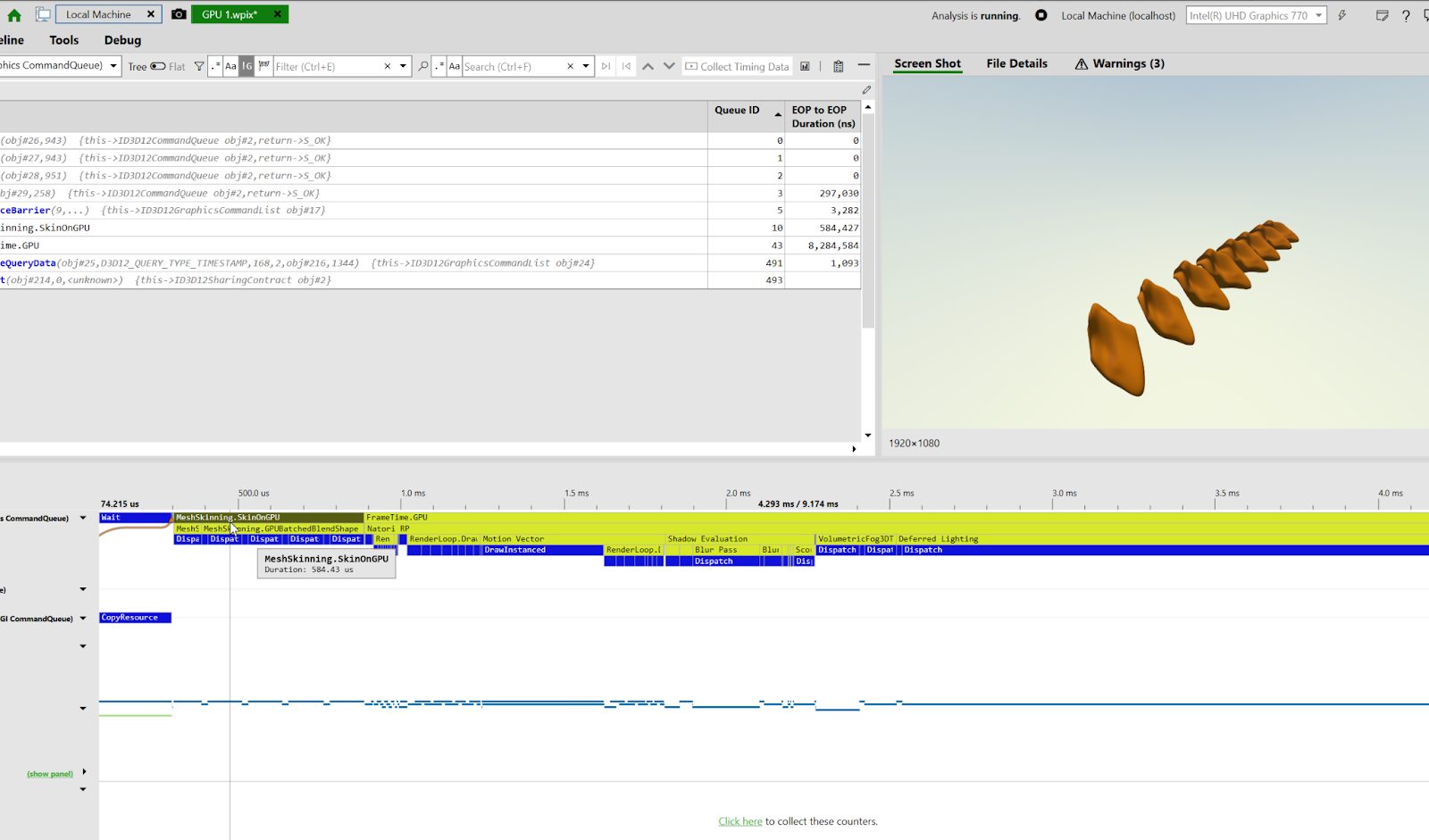
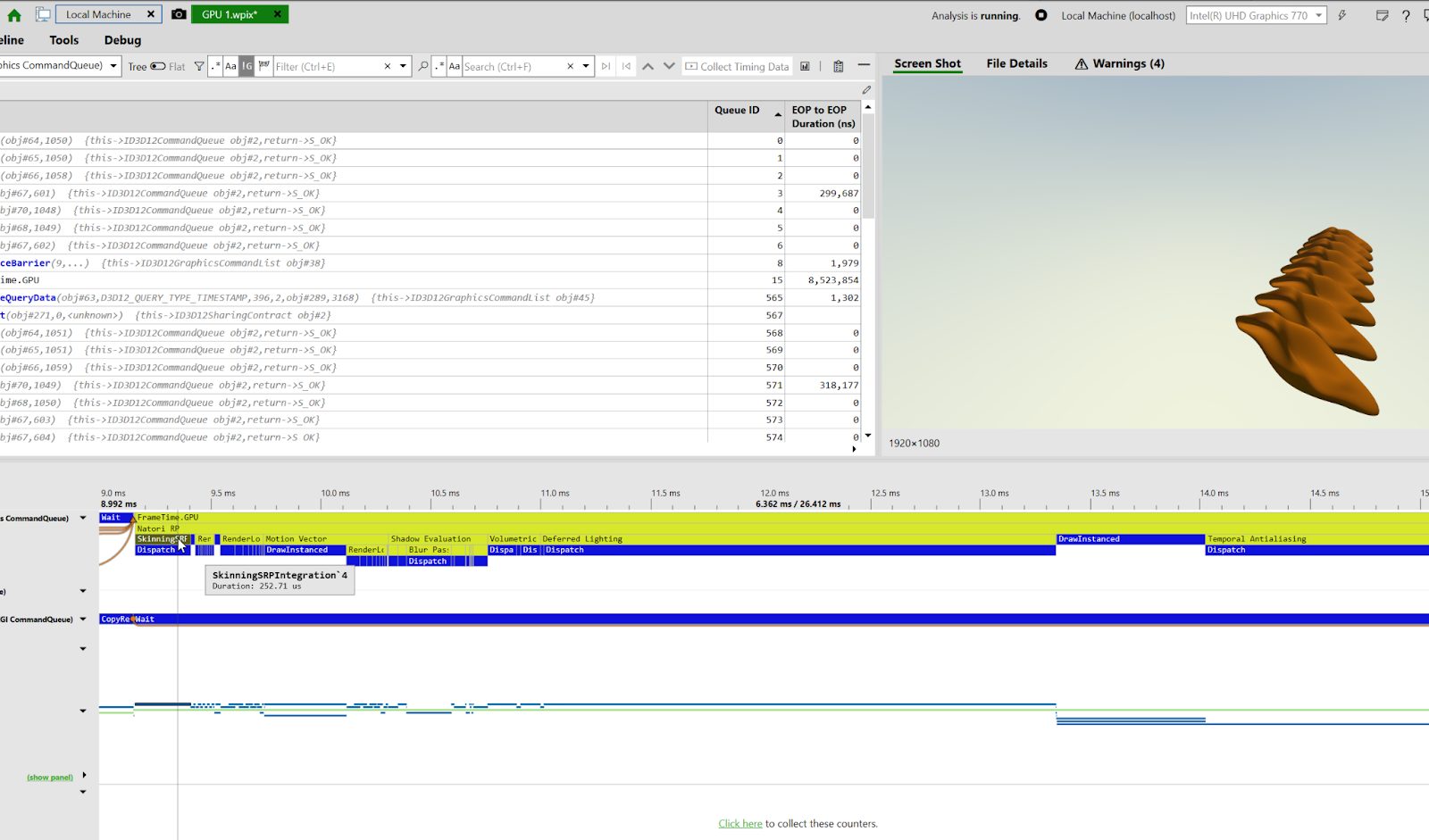
続いて独自手法ですが、以下の画像のように253msほどでした。処理時間が半分以下になりましたね!大勝利です。Dispatchは方針通り、一回のみに収まっております。
1つのBlendShapeが有効な時の計算時間
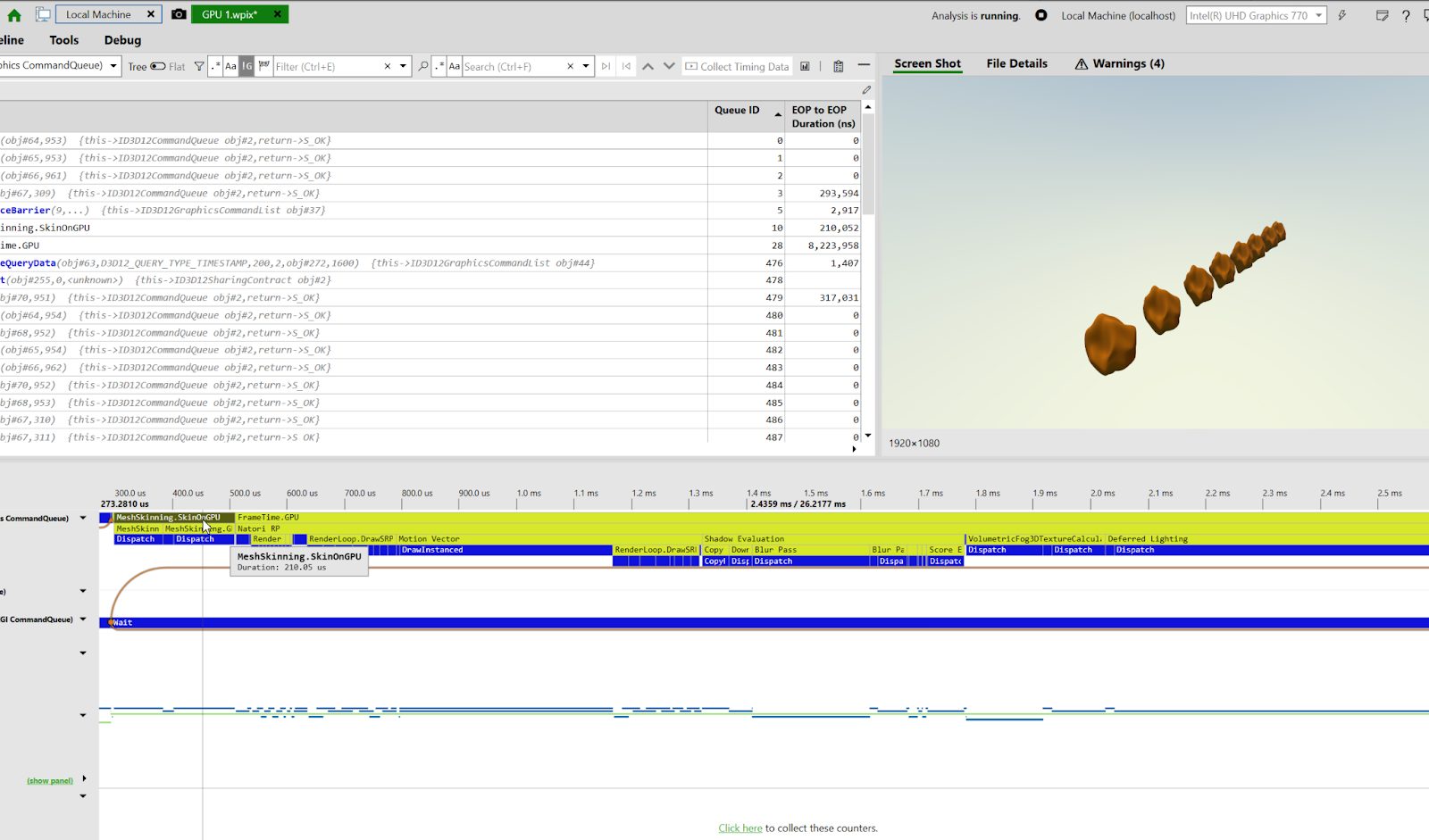
今度は一つだけBlendShapeを与えたケースです。UnityのSkinnedMeshRendererでは以下の画像のように210msほど掛かりました。
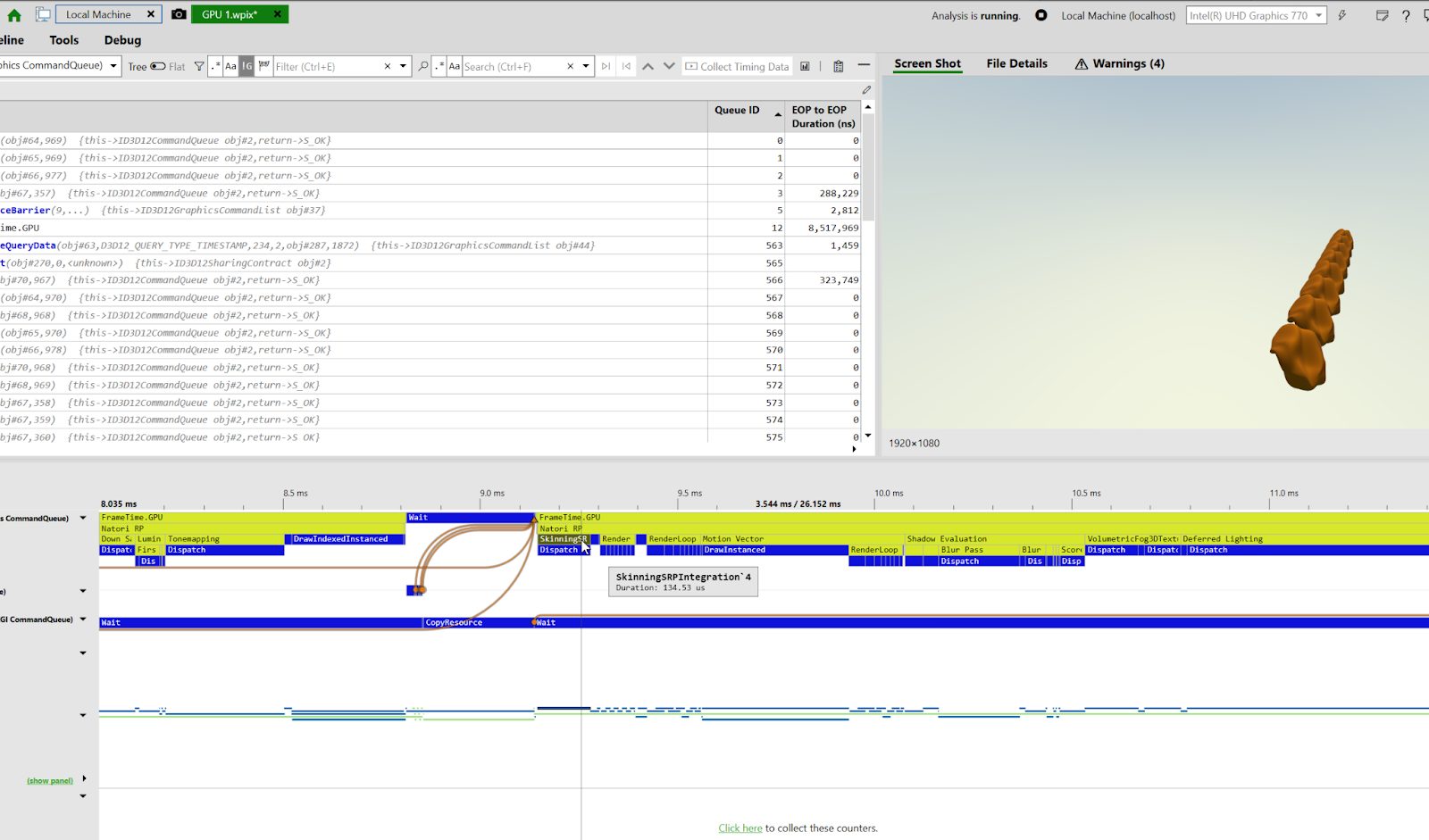
続いて独自手法ですが、なんと135msほどでした。こちらも処理時間が60%くらいにまで短くなってますね!驚きです。
4つのBlendShapeが有効な時は期待通りに処理時間が短くなり、なべて世はこともなし!なのですが、1つのBlendShapeだけが有効な場合でも結構な高速化がなされています。これは期待しておりませんでしたね。
上の画像をよく見ると、UnityのSkinnedMeshRenderer側では1BlendShapeの時も2回Dispatchが呼ばれているので、主な差異はその当たりでしょうか。パっと見謎のコピー用シェーダが走っているようです。
不要な処理に感じましたが、互換性のためのものかもしれません。殆どのモダンな環境では実際無駄な処理でしかないのですが、一部の環境ではSSBOのバインド数の制限が厳しめに置かれてるため、RWにして8つ処理出来るようにしてるのでしょう。そういえばUnityはスキニングについて5個をBatch単位にしており、中途半端な数に思えていたのですが、こちらも互換性のためなのでしょうね。
一旦私の実装ではこの件を無視しましたが、後日コンピュートでのバインディング上限が厳しめのハードウェアについての対応も、保守的にするのではなく両立する形で行います。(何言ってるか分からないかもしれません。あまり重要でないので気にしなくて大丈夫です。)
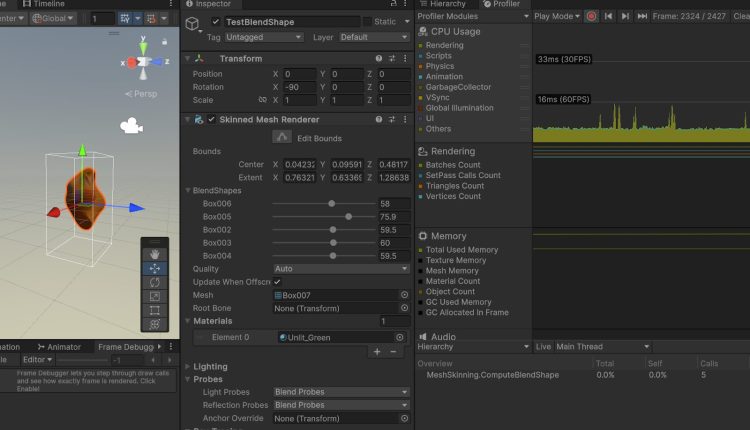
もう一つ、計測に表れない部分のパフォーマンス話なのですが、実はUnityのSkinnedMeshRendererではBlendShapeの値に変動がなくとも毎フレーム必ず計算が発生しております。これは無駄なため、私の実装ではBlendShapeの値に変化がない場合は計算を省くような形にしました。
似たような話はスキニング処理にもあり、Unityはボーンを持ったモデルのSkinnedMeshRendererでの描画について、アニメーション再生していないような状況でもスキニングを発生させております。(ボーンのTransformがいつ何の理由で変更されるかが分からないから保守的な対応をしているのでしょう。)こちらのスキニングについても、私の実装ではクライアント側で評価を指示した時(アニメーション計算グラフの評価を指示した際)のみ計算するようにしました。
つまり、私の実装ではスキニングやブレンドシェイプ計算の頻度を、描画フレームレートから独立させることが出来るようにしているということです。例えば画面上のピクセルを占める範囲が小さい、遠くにあるようなオブジェクトについて、アニメーション・スキニングの計算頻度を落とすことが出来るわけですね。コンシューマーゲームでは割と昔から見られる、恐らく一般的な最適化手法なのですが、Unity公式のSkinnedMeshRendererでは実現できないためUnity製のゲームでは通常見かけません。コーナーで差をつけろ!
おわりに
GPUの処理軽減はそれなりにダルいです。発想自体は簡単なことも多いのですが、GPUに対する理解が必要です。また大量の対象を捌くような今回のケースでは、スケジューリング回りが複雑になることでCPU側の実装難易度がドカンと高くなりがちです。難しいだけならともかく、うまくマルチスレッドJob化しなければ、CPUパフォーマンスに問題が起きるような事もあります。
しかも今回のBlendShapeやスキニングの置き換えのようなテーマは、BRGを独自で利用できるようにし、Animatorまで独自で置き換え……というようなハードルがあり、とても万人が全てのプロジェクトで実施・利用できるものではないです。技術的な実装だけならともかく、設計と運用的に成功させるにはそれなりの知識が必要でしょう。
それでも、今のUnityでこれだけのことが可能だという事実は重要だと思いませんか?Unityの公式ソリューションが決して限界ではないということは、時折我々の選択を怠慢として映し出すわけですからね。色々な視点をもって頑張ってみましょう!
次回は、予告通り後編を書きます。今月中くらいに書けたらいいな……
★ILでは3Dゲーム開発にも取り組んでおります。興味がある方は是非採用情報をご確認ください。★
追記
今回BlendShapeで異様にパフォーマンス差が出て、スキニングについても一つ気付いたことがありました。
前編で用意していた検証用のペンギンモデルは一つの頂点に最大で影響するボーン数が2だったのですが、僕のスキニングのコードは任意数のボーン影響を受けられるものでした。モデル側を事前に分析しておいて、ありがちな最大ボーン影響数(2までとか4までとか)だった場合はループの無いシェーダで特別扱いをした方が良いかもしれません。
ありがちなボーンに収まる多くのモデルで動的ループによるレジスタのプレッシャーを無くすことができるはずですから、環境によってはもう少しパフォーマンスを上げられる気がします。きちんと検証はできておりませんが、Unity公式もそういうことをやっているかもしれません。(処理が三通り用意されていたので。)後で見てみます。

