久々に記事を書きます。今回はd3d12やUnityの描画話ではなく、SIMDの話をします。SIMDコーディング歴三日で。ええ!?素人じゃん!
個人的に、GPUプログラミングと比べてCPUのSIMDは得られる利益のわりに意味不明に見えてしまっており、これまで殆ど無視していました。
そもそもゲーム開発の一体どのシナリオで、SIMDがおいしいのか。
事前のアセット加工ですか?いや、ユーザーの手元で動かないコードに苛烈な最適化をする価値はほとんど見込めないのでは。ではゲームロジック……うーん、
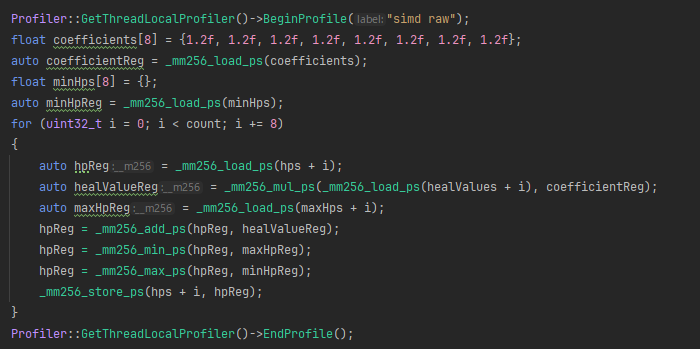
上は、わざとらしいゲームロジックである「HPの回復計算」がテーマのAVX向けのコードです。正しく動くかは知らん。てかなんで回復なのにmin比較してるんですかね?ところで、Windows向けとして実用的にするには、SSE向けに似たようなコードをもう一つ記述し、動的に分岐する必要があります。うっそでしょ!
SIMDは書くのが大変そうですよね!ってか読みづらい。こんなコード中学生に見せたら泣いてしまうかもしれない。_mmってなんやねん。これは一つのゲーム開発での問題かもしれません。
ゲーム開発はタイトル毎に固有のコードが発生しやすいわけです。意味があるのかもわからない改善のために、異常な怪コードを書いていこう、という気持ちには中々なりません。限定的な適用になるでしょう。
どうにかこの辺をいい感じにやれる層を挟み込むことができれば、もう少し使用範囲が広がるかもしれないわけですが、少しでもリッチなものを入れると非SIMDで記述したコードのコンパイラ自動最適化に速度でけちょんけちょんにされます。されました。(一敗)
コンパイラ(MSVCしか僕は知らない)の自動最適化は十分に有能なため、SIMDのカジュアルな利用など正直検討しなくてもよい気はするのですが、どうにかやってみたい!少なくとも使えないかは一度検討しておいて、ムリならしっかりあきらめておきたいですよね。
- CPUフィーチャー/プラットフォーム対応が都度は不要。一か所に封じ込められる
- 素朴な表現にパフォーマンスで勝てるSIMD抽象化であること
- C++の文法内で完結している
この辺りを狙ってやってみましょう。
結論
以下、どんな感じになったかです。

上の画像のように、クライアント側でのSIMD計算呼び出しは一行で済むようになりました。ここは間違いなく及第点でしょう。SimdComputeクラスでは、単一のC++実装記述のみを持ったSimdHPCalculationSampleクラスを、環境で利用されるべきSimdで実現した挙動について、動的ないし静的に呼び出されるようにしております。その実行が上の画像のDispatch関数です。
さて、SimdComputeは以下のように定義されております。
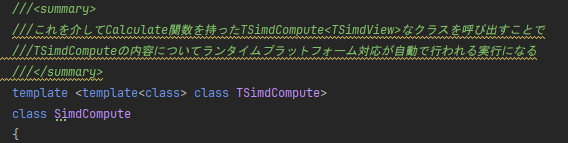
SimdHPCalculationSampleクラスは、TSimdComputeに割り当てられるクラスなわけですが、これはテンプレートとしてSimdの具体的な実装を受け取るようになっているのですね。
そして、計算の詳細であるSimdHPCalculationSampleクラスは以下のようなものです。最初にAVXで記述した、病的な体力計算と同等のものです。TSimdViewはSimdの具体的な実装をされたクラスであり、simdContextを介して様々な操作を行います。
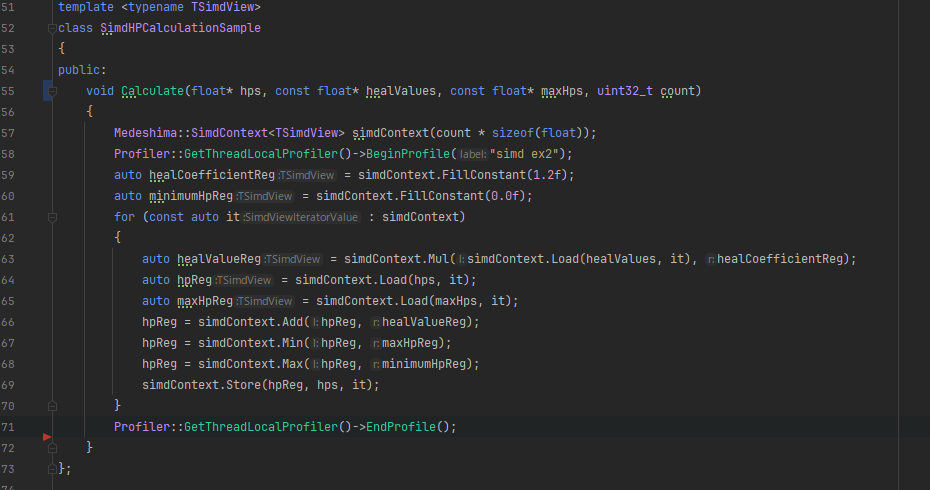
ここでの工夫はささやかなものです。
例えば、SimdCompute側のDispatchが可変長引数に対応しているため、ここでのCalculate関数は任意の入力を持つことができます。また、実際にsimdレジスタとやりとりしている体をなしているSimdContextについては、様々な命名から_mmで始まるような異質さを排除している点と、イテレータでSimd幅に関係なくループを消化していくようにしている点がポイントです。(C++素人すぎて初めてイテレータ使ったわ)それと、定数を簡単にレジスタに置いておく便利機能などもあります。これで、いくらか人間が読めるのではないでしょうか。泣き止んでくれるかな。
なお、明らかですがTSimdViewはSimdContextが要求する関数を適切に実装されたものである必要があります。これらはパフォーマンス上の理由で静的な結合にするため、インターフェースなどを残念ながら要求として設けておりません。
とりあえず、これを一つ記述するだけでSSEやAVXに向けて同等の実装が吐き出されるということは確かです。やったね。
ちなみに、等価なナイーブ表現は以下です。そりゃやっぱこっちのほうが読みやすいし書きやすいよねー。
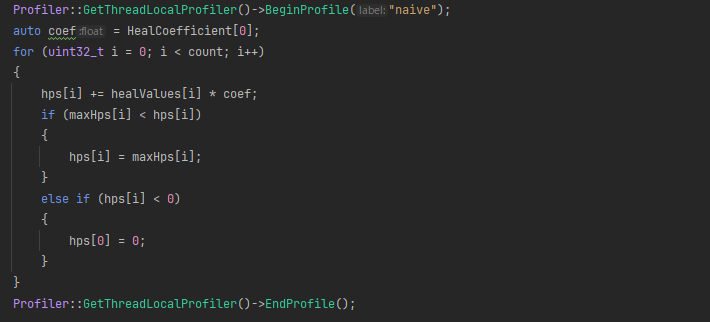
だから、なんで回復なのに0チェックしてるんですかね?そこ、静かに。
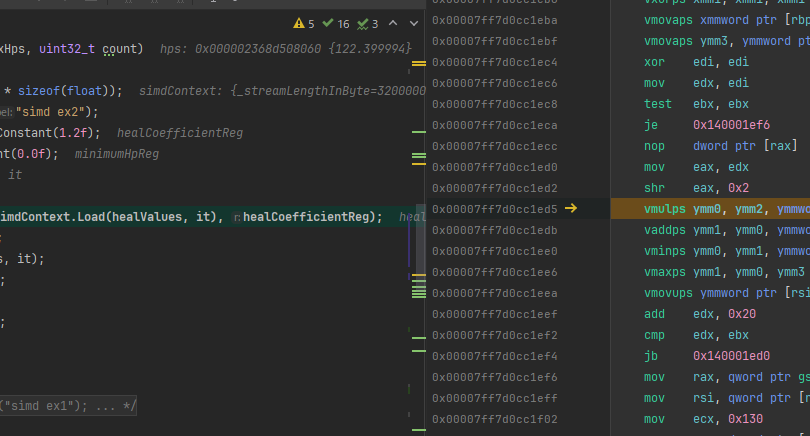
ディスアセンブル結果
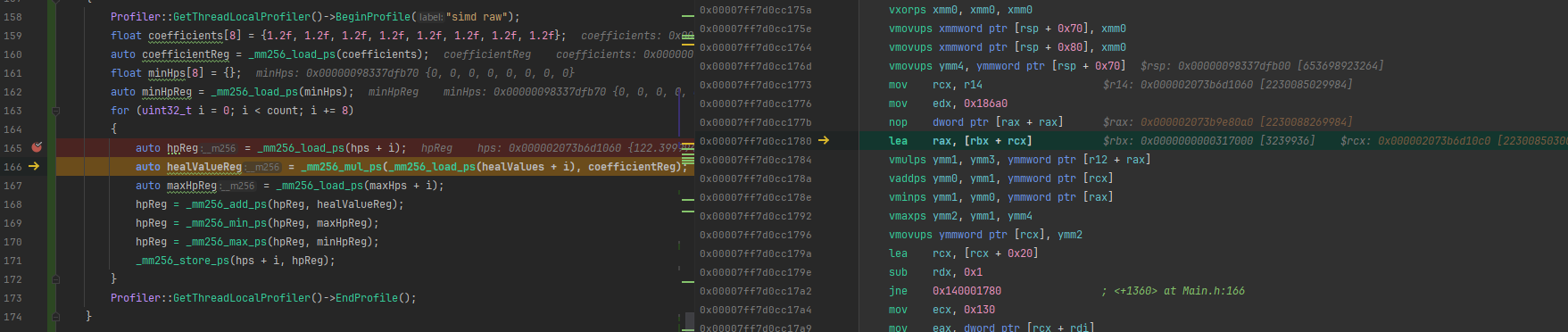
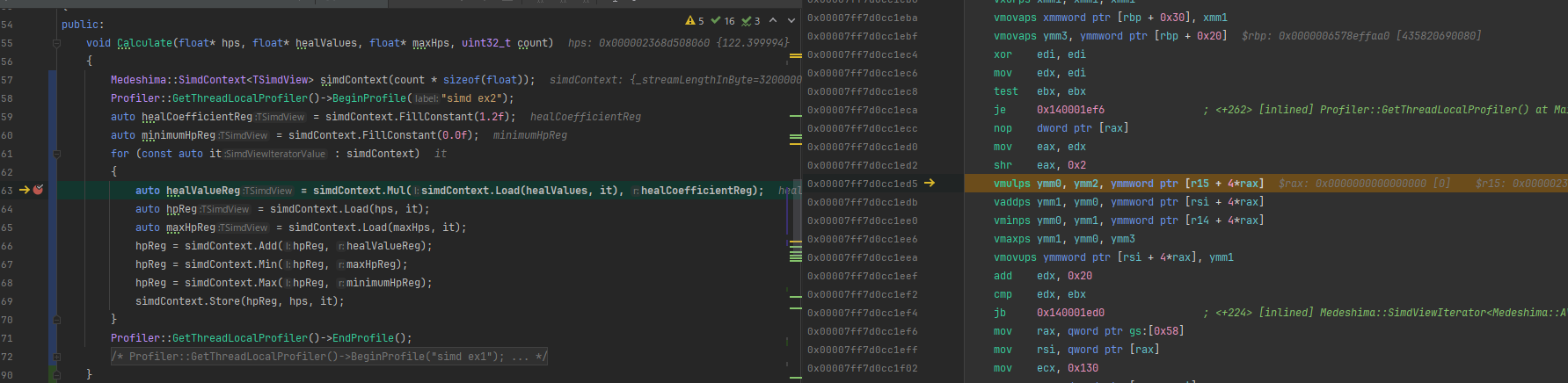
適当に撮影してますので、ちゃんと映ってない可能性があります。(え?)
ざっと見た感じ今回の抽象化は生で書いてるのとほぼ同じっぽい!ぽくない?
速度はフェアな検証が難しかったため載せませんが、今回のケースでは計算対象が十分に多い場合、AVX生およびSimdCompute+AVXは、素朴な表現に対して計測環境では3、40%くらい速度で勝っている雰囲気がありました。
おわりに
プラットフォーム、CPUフィーチャー分岐対応や可読性はマシにはなりましたが、なんかコンピュートシェーダっぽいというか。色々。今回の例でもメモリやり取りがネックだったし。演算を埋めるのが大変だ。
やはり限定的な利用くらいですかねえ。もうちょっと本格的に活用し始めたら色々拡張などするかもしれませんが。ゲームでSIMD……物理系の実装とかですかね?
★インフィニットループでは3Dゲーム開発にも取り組んでおります。興味がある方は是非採用情報をご確認ください。★

