
最近 AI 関係のソフトウェアに触れる機会が増えてきたインフラエンジニアの波多野です。
AI といえば大規模言語モデル (LLM) で、日本語を扱えるサービスも ChatGPT や GitHub Copilot などいくつか出ています。いずれも「もうチューリングテストに合格しているのではないか?」くらいの性能で、今後のことを考えるとワクワクしています!
ところで、PC にちょっと変わった Linux をインストールしてみたり、いつもと違うデータベースやプログラミング言語入れるなど、スタンドアローンなソフトウェアを使うことにはそれでしか味わえない楽しみがありますよね。上記の著名なLLMサービスはクラウドで提供されていますが、今回は ChatGPT のような日本語 LLM を手元の PC で動かすこと に挑戦してみました!
llamafile とは
大規模言語モデル (LLM) のモデルはクローズドソース/オープンソース含めていくつかありますが、Meta 社がオープンソースで公開したのが Llama 2 https://llama.meta.com/llama2 (ラーマと読むらしい)です。
その Llama2 を PC でローカルに扱えるように Python の PyTorch を使わず C で実装したのが Georgi Gerganov 氏の llama.cpp https://github.com/ggerganov/llama.cpp で、llama.cpp は x86_64 にも対応していますが当初は Mac の Apple シリコンで動かすことを意識して開発されたそうで、Windows でのビルドは環境整備含めると若干難易度が高いところはあります。
llama.cpp を、軽量かつ複数 OS で実行可能な x86_64 exe ファイルを生成する cosmopolitan libc で移植し、OpenAI 互換の API サーバー機能を足したものが Mozilla の実験プロジェクト Ocho で Justine Tunney (jart) 氏が開発した llamafile https://github.com/Mozilla-Ocho/llamafile になります。
この llamafile はモデルも同梱されていますが、仮にモデルを除けば本体部分はわずか 30MB 程度と扱いやすい優れもので、今回はこちらをインストールして動かしてみました!
Windows PC で llamafile を使ってみる
今回使用したのは以下のスペックのデスクトップ PC で、GPU 付ではあるものの CPU は年季が入っていたり、ほどほどなスペックだと思います。それでも今回の実験通して性能が余っていましたので、もう少し低いスペックでも動ける可能性があります。
- GPU : RTX 3060 (VRAM 12G)
- CPU : i5-9400F
- メモリ : 32GB
- OS : Windows 10
Quickstart https://github.com/Mozilla-Ocho/llamafile?tab=readme-ov-file#quickstart に沿って以下の流れでインストールして動かします。
- https://huggingface.co/jartine/llava-v1.5-7B-GGUF/resolve/main/llava-v1.5-7b-q4.llamafile (3.97GB) をダウンロードします。将来 llamafile や同梱モデルの llava のバージョンが変わった場合も、7B パラメーターを学習した 4bit 量子化 (q4) 済みで 4GB 未満のものを選べば問題ないです。
-
ダウンロードしたファイルの末尾に .exe を付けます。
- コマンドプロンプトで llava-v1.5-7b-q4.llamafile.exe -ngl 9999 を実行します。(ngl は NVIDIA/AMD GPU へ処理を渡す割合で 9999 の最大にします)
- GPU を上手く認識していると起動時のメッセージには以下のようなログが含まれます。

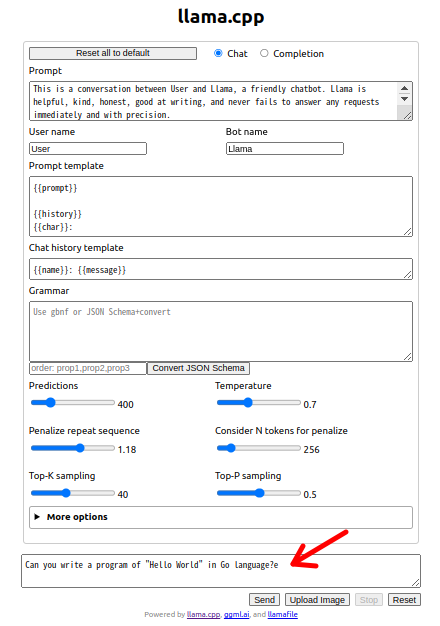
- ブラウザで http://127.0.0.1:8080 が自動で開くか、開かない場合は手動でアクセスしてください。ポート 8080 が使用中の場合は 8081 等別ポートを自動で使います。簡素な縦長のプロンプト画面が表示されますので一番下のボックスに書いて話しかけます。(デフォルトの LLaVA は英語のみのモデルなので英語で)
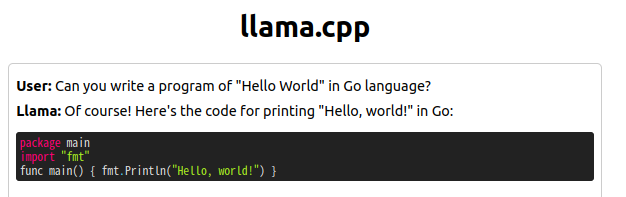
- 例えば “Can you write a program of “Hello World” in Go language?” と尋ねると以下の様に即答してくれます。

東工大の日本語モデル Swallow を試してみる
同梱されている 7 億バラメーターの LLaVA 7B は英語での応答になりますが賢くて快適にやりとり出来ています! とはいえ日本語でのやりとりをしたいところなので日本語の LLM を探したところ、東京工業大学情報理工学院 TokyoTech-LLM 様 https://tokyotech-llm.github.io にて公開されている Swallow というモデルを見つけましたのでそちらを試してみました!
gguf 形式変換済み Swallow 7B のダウンロード
本来ですと最初に huggingface.co にて公開されている Llama 2 形式の本家(東工大)の Swallow 7B をダウンロードし、次に llama.cpp の GitHub リポジトリも clone して手元に持ってきてビルドを行い、convert.py にて Swallow 7B を llama.cpp の 32 ビット gguf 形式に変更します。変換結果ですが 27GB くらいのサイズがありそのままでは RTX3060 PC ではとても使えませんので、さらに quantize.exe ツールで 4ビットに量子化することで自分の PC でも扱えるサイズの gguf モデルを取得します。
ビルドが無事でツールが揃っていればコンバートや量子化も難しくはないですが、Windows 上でのビルド環境整備がやや難易度が高いため、今回は HuggingFace 上ですでに同様の変換を行ってくれている有志の方 (TheBloke 氏) の 4bit 量子化済みミディアムサイズの Swallow 7B 変換済みモデルを利用させて頂きました。
https://huggingface.co/TheBloke/Swallow-7B-GGUF/blob/main/swallow-7b.Q4_K_M.gguf にアクセスし、Download ボタンでダウンロードします。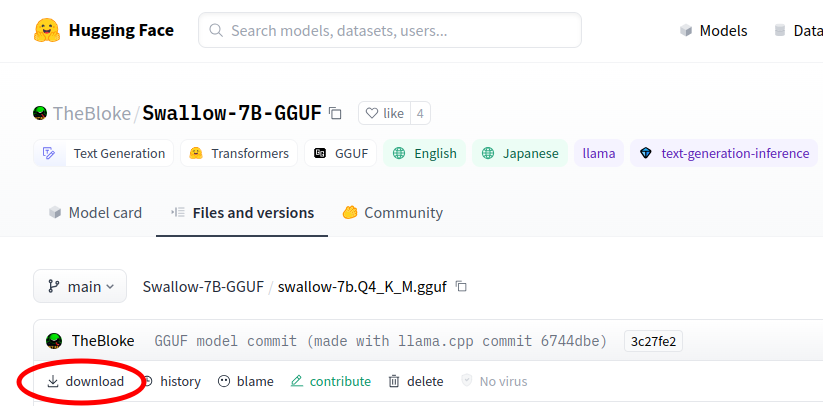
実行時に Swallow を指定して llamafile を起動する


