
こんにちは。myxyです。
冬も深まりいよいよGPUの排熱が恋しくなる寒さになってきました。
GPUで効率よく暖を取るためには計算資源を無駄なく使う工夫が必要になります。
この記事では単純な例としてMNIST数字認識データセットのオートエンコーダの実装を通じてマルチGPUによる機械学習に触れてみます。
コードはGitHubに公開しています。
検証環境は以下の通りです:
| CPU | RAM | GPU |
|---|---|---|
| Ryzen Threadripper 1950X | 128GB (DDR4 16GB x8) | RTX3090 x2 |
オートエンコーダとは(シングルGPU学習)
一般にオートエンコーダは与えられた高次元のデータをより低い次元の潜在空間上にマップするEncoderと潜在空間から元のデータへ復元するDecoderで構成されます。
近年話題のStableDiffusion等の潜在拡散モデルではオートエンコーダ(VQVAEを使っているようです)の潜在空間上で生成を行うことで計算量の削減をしています。
この記事ではMNISTデータセットの28×28の数字画像を32次元のベクトルに変換するオートエンコーダを作ります。
まずは単一GPUでのオートエンコーダの学習を書いてみます。
学習モデルは次の通りです:
class Encoder(nn.Module):
def __init__(self, width, height, hidden_dim):
super().__init__()
self.width = width
self.height = height
self.conv1 = nn.Conv2d(1, 8, 3)
self.conv2 = nn.Conv2d(8, 64, 3)
self.fc = nn.Linear((width-4)*(height-4)*64, hidden_dim)
self.act = nn.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.act(x)
x = self.conv2(x)
x = self.act(x)
x = x.view(-1, (self.width-4)*(self.height-4)*64)
x = self.fc(x)
return x
class Decoder(nn.Module):
def __init__(self, width, height, hidden_dim):
super().__init__()
self.width = width
self.height = height
self.act = nn.ReLU()
self.fc = nn.Linear(hidden_dim, (width-4)*(height-4)*64)
self.conv2 = nn.ConvTranspose2d(64, 8, 3)
self.conv1 = nn.ConvTranspose2d(8, 1, 3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.fc(x)
x = x.view(-1, 64, self.width-4, self.height-4)
x = self.act(x)
x = self.conv2(x)
x = self.act(x)
x = self.conv1(x)
x = self.sigmoid(x)
return x
class AutoEncoder(nn.Module):
def __init__(self, width, height, hidden_dim):
super().__init__()
self.encoder = Encoder(width, height, hidden_dim)
self.decoder = Decoder(width, height, hidden_dim)
def forward(self, x):
z = self.encoder(x)
x_hat = self.decoder(z)
return x_hat, z
EncoderはCNN2層と全結合層、DecoderはEncoderと逆の構造となるよう構成しています。
モデルをGPU上に構築して訓練してみましょう、訓練時間も計ってみます。
width = 28
height = 28
hidden_dim = 32
model = AutoEncoder(width, height, hidden_dim).cuda()
model.train()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters())
batch_size = 32
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=os.cpu_count(), pin_memory=True)
num_epochs = 10
train_start = time.time()
for epoch in range(num_epochs):
pbar = tqdm(train_loader, desc=f'epoch {epoch}')
for batch in pbar:
inputs, _ = batch
x = inputs.view(-1, 1, width, height).cuda()
optimizer.zero_grad()
x_hat, z = model(x)
loss = criterion(x_hat, x)
loss.backward()
optimizer.step()
pbar.set_postfix(loss=loss.item())
train_end = time.time()
train_time = train_end - train_start
print(f'train time: {train_time}')
テストデータの先頭5枚の画像を学習したオートエンコーダに通して圧縮・復元をしてみましょう。
以下のコードで画像として書き出します:
model.eval()
num_figs = 5
plt.figure(figsize=(num_figs, 3))
for i in range(num_figs):
input, label = test_dataset[i]
x = input.view(1, 1, width, height).cuda()
x_hat, z = model(x)
ax = plt.subplot(3, num_figs, i+1)
plt.imshow(x.cpu().detach().numpy().reshape(width, height), cmap='gray')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, num_figs, i+1+num_figs)
plt.imshow(z.cpu().detach().numpy().reshape(1, hidden_dim))
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, num_figs, i+1+num_figs*2)
plt.imshow(x_hat.cpu().detach().numpy().reshape(28, 28), cmap='gray')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.savefig('outputs/compare.png')
これにより以下のような画像ができます。上段が入力画像、中段が圧縮後の32次元ベクトル、下段が32次元ベクトルからの復元画像です。
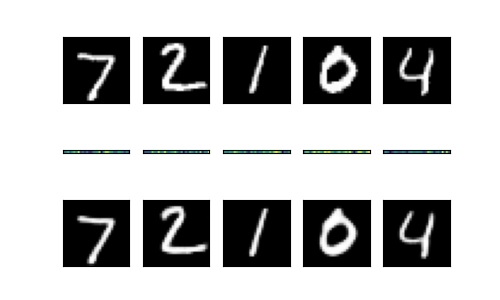
マルチGPU学習
マルチGPUでの学習・推論ではモデルを分割して配置するデバイスを明示的に指定します。また、入力されるTensorも適切なデバイスに転送する必要があります。
今回はGPUを2つ使用し、EncoderとDecoderを別々のデバイスに配置します。
class AutoEncoder(nn.Module):
def __init__(self, width, height, hidden_dim):
super().__init__()
self.encoder = Encoder(width, height, hidden_dim).cuda(0)
self.decoder = Decoder(width, height, hidden_dim).cuda(1)
def forward(self, x):
device = x.device
x = x.cuda(0)
z = self.encoder(x)
z = z.cuda(1)
x_hat = self.decoder(z)
return x_hat.to(device), z.to(device)
モデルやTensorをGPUに転送するには.cuda(0)や.to('cuda:0')のメソッドが使えます。
転送系のメソッドには次のようなものがあります:
| メソッド | 効果 |
|---|---|
.cuda() | 現在選択中のGPU(torch.cuda.current_device()で取得できる)に転送 |
.cuda(n) | n番目のGPUに転送 |
.cpu() | CPUに転送 |
.to(device) | deviceには'cpu','cuda','cuda:0'等指定できる |
訓練のコードはほとんど変えていませんが入力Tensorの転送先に明示的に.cuda(0)を指定するようにしました。
train_start = time.time()
for epoch in range(num_epochs):
pbar = tqdm(train_loader, desc=f'epoch {epoch}')
for batch in pbar:
inputs, _ = batch
x = inputs.view(-1, 1, width, height).cuda(0)
optimizer.zero_grad()
x_hat, z = model(x)
loss = criterion(x_hat, x)
loss.backward()
optimizer.step()
pbar.set_postfix(loss=loss.item())
train_end = time.time()
train_time = train_end - train_start
print(f'train time: {train_time}')
シングルGPUとマルチGPUを比較した計算時間は次のようになりました:
| 学習方法 | 10epoch回した時間(秒) |
|---|---|
| シングルGPU | 103.67 |
| マルチGPU | 112.99 |
マルチGPUの方が時間がかかっていますね。
GPUパイプライン
単一モデルをマルチGPU向けに分割するとシングルGPUに乗らないサイズのモデルを計算できるというメリットはありますが、Tensorの転送等のオーバーヘッドが発生しシングルGPUよりも遅くなります。
単純に複数GPUを使ったからといって速くなるわけではもちろんないです。
先ほどのマルチGPUのコードでは下図のように一つのGPUが計算をしている間他のGPUが遊んでおりGPUの利用効率が極めて悪いです。
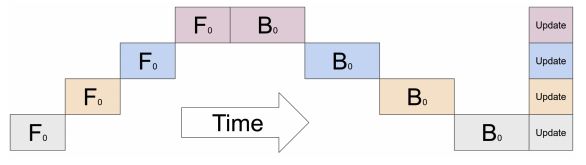
マルチGPUで高速化のメリットを得るにはGPUが並列に動作するようにパイプラインを構成する必要があります。
Pipeline Parallelism — PyTorch 2.1 documentation
https://pytorch.org/docs/stable/pipeline.html
モデルに一度に流し込むバッチをマイクロバッチに分割してパイプライン並列で計算することでGPUの利用効率を上げることができます。
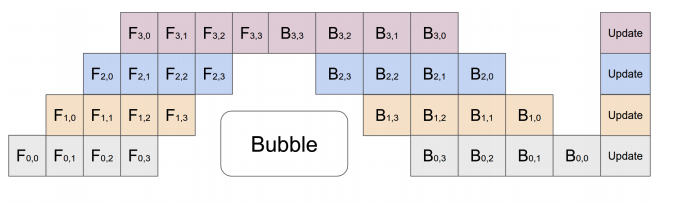
PyTorchでのニューラルネットワークの学習においては順伝播(forward)と逆伝播(backward)でモデルをデータが流れる向きが変わるため、図のようにforwardとbackwardの間にパイプラインバブルが発生します。
このパイプラインバブルについてはバッチからマイクロバッチへの分割数を増やすことにより計算時間への影響を減らすことができます。
torch.distributed.pipeline.sync.Pipe()に渡すモデルはnn.Sequential()の形である必要があるためAutoEncoderクラスにEncoderとDecoderをnn.Sequential()でつなげて返すメソッドを生やします。
これをPipe()に渡してできたモデルをmodel_pipelineとします。
class AutoEncoder(nn.Module):
def __init__(self, width, height, hidden_dim):
super().__init__()
self.encoder = Encoder(width, height, hidden_dim).cuda(0)
self.decoder = Decoder(width, height, hidden_dim).cuda(1)
def forward(self, x):
device = x.device
x = x.cuda(0)
z = self.encoder(x)
z = z.cuda(1)
x_hat = self.decoder(z)
return x_hat.to(device), z.to(device)
def model_pipeline(self):
return nn.Sequential(self.encoder, self.decoder)
width = 28
height = 28
hidden_dim = 32
model = AutoEncoder(width, height, hidden_dim)
model.train()
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
torch.distributed.rpc.init_rpc('worker', rank=0, world_size=1)
chunks = 8
model_pipeline = Pipe(model.model_pipeline(), chunks=chunks)
model_pipelineに渡されるTensorはchunksで指定された数のマイクロバッチとして分割された後パイプラインで並列に処理されます。
各GPUが一度に処理するマイクロバッチサイズはマルチGPUとの計算時間比較のため揃えたいので、DataLoaderのバッチサイズはchunks倍しておきます。勾配計算はバッチサイズ単位で行われるため完全に等価な学習ではないですが今回は計算時間に着目したいため無視することにします。
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size*chunks, shuffle=True, num_workers=os.cpu_count(), pin_memory=True)
学習コードはマルチGPUのときとほぼ同じですがmodel_pipelineの出力はRRef型(将来的に複数ノードパイプラインに対応するためらしい)なので.local_value()で値を取り出すようにしています。
train_start = time.time()
for epoch in range(num_epochs):
pbar = tqdm(train_loader, desc=f'epoch {epoch}')
for batch in pbar:
inputs, _ = batch
x = inputs.view(-1, 1, width, height).cuda(0)
optimizer.zero_grad()
x_hat = model_pipeline(x).local_value()
loss = criterion(x_hat, x.cuda(1))
loss.backward()
optimizer.step()
pbar.set_postfix(loss=loss.item())
train_end = time.time()
train_time = train_end - train_start
print(f'train time: {train_time}')
計算時間は次のようになりました:
| 学習方法 | 10epoch回した時間(秒) |
|---|---|
| シングルGPU | 103.67 |
| マルチGPU | 112.99 |
| GPUパイプライン | 130.96 |
パイプライン無しより遅くなっていますね。
…
どうして…
Pipe()のcheckpointパラメータ
詳しく調べたところPipe()構築時のオプションパラメータcheckpointが関係していることがわかりました。
この引数についてはPyTorchのPipeline Parallelismのページには殆ど説明は無かったものの、Pipeの元になったGPipeのドキュメントに詳しい説明があります。
通常forwardメソッドで順伝播を計算する際に逆伝播に必要な値が保存され、backwardメソッドで値が再利用されます。一方checkpointingが有効の場合、逆伝播に必要な値を最低限必要な値以外忘れてbackward時に再計算することによりVRAMを節約できる、という仕組みのようです。Pipe()のデフォルトではcheckpoint='except_last'が指定されており最後のマイクロバッチ以外ではcheckpointingが有効となっています。
checkpoint='never'でcheckpointingを無効化してもう一度学習してみます。
model_pipeline = Pipe(model.model_pipeline(), chunks=chunks, checkpoint='never')
計算時間は次のようになりました:
| 学習方法 | 10epoch回した時間(秒) |
|---|---|
| シングルGPU | 103.67 |
| マルチGPU | 112.99 |
GPUパイプライン(checkpoint='except_last') | 130.96 |
GPUパイプライン(checkpoint='never') | 87.23 |
ちゃんと高速化ができていますね。
chunksの値を増やしてパイプラインを長くした場合についても比較してみました:
| 学習方法 | 10epoch回した時間(秒) |
|---|---|
GPUパイプライン(checkpoint='never', chunks=8) | 87.23 |
GPUパイプライン(checkpoint='never', chunks=16) | 79.36 |
GPUパイプライン(checkpoint='never', chunks=32) | 75.99 |
パイプラインが長くなるほどパイプラインバブルの影響が減り計算時間が短縮されているのがわかります。
まとめ
記事を書く過程でPipe()のcheckpointパラメータについての知見が得られたので良かったです。checkpoint='never'指定は高速化できる一方でVRAM消費が激しく、別で動かしている1.6Bパラメータのモデルで試したところVRAM不足で動きませんでした。軽量なモデルであれば大きな効果を得られると思います。
ILではAI技術を利用したプロダクトの開発にも取り組んでいます。興味をお持ちの方は是非採用情報をご覧ください。

