こんにちは。学生アルバイトリーダーのyutoです。
今回は、弊社が運営する勤怠管理サービス「シュキーン」のデータを分析し、過去6年間の勤怠事情の変化を追ってみました。
なお、学生アルバイトによるデータ分析はシュキーンから取得した過去の当社従業員全打刻データを専用環境に投入し、そちらで実施しています。
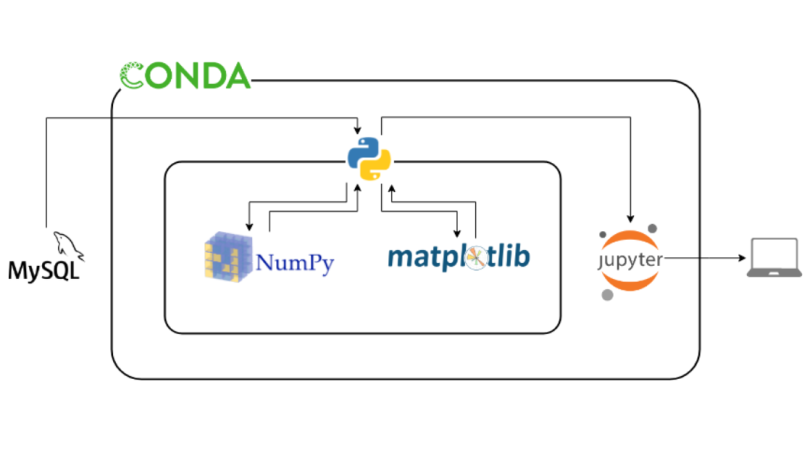
利用した技術
– Python3
データ分析に必要なライブラリが豊富なため使用しました。
– Jupyter Notebook
ブラウザで動作するプログラムの対話型実行環境のことです。
プログラムの記述と実行、それにメモを付けることができます。また、グラフも描画できるためチームでPythonの実行結果を共有する際に非常に便利であるため使用しました。
– Anaconda
後述するライブラリを含めた環境を構築するために使用しました。
└ Numpy(計算)
Numpyは計算用のライブラリであり、多次元配列の数値データを対象とした計算を得意としています。
そのため、データ分析や機械学習によく使われます。
└ matplotlib(グラフ描画)
上記のNumpyで計算した結果をグラフで描画したかったため使用しました。
– VirtualBox
仮想マシンのこと。WindowsPCでもLinuxなどのOSを扱うことができます。
– Vagrant
上記した仮想マシンを利用するには様々な設定が必要です。vagrantはその設定を簡単なコマンドで行ってくれるツールです。
さらにその環境を配布でき、チームで簡単に同じ環境で作業を進められるため使用しました。
– GitLab
OSSのGitHubクローンのようなもので、チーム作業に便利な機能が多くあります。
– Generated Column
MySQLの機能の一つ。他のカラムから計算した結果を新しいカラムとして定義できます。シュキーンのデータベースにはタイムスタンプしか保存されていないため、曜日をタイムスタンプから計算する必要があり、この計算に利用しました。
チームの動き
全員のシフトがバラバラなので作業を共有できるツールを使用しました。
一人しか出社していなくとも各自作業ができる環境にし、それぞれ進捗状況の報告をしてもらいました。
環境を統一するためにVagrant,VirtualBox,JupyterNotebook
ソースコードの管理にはGitLab、さらにGitLabのissue機能を使用することでチームのタスクを管理しました。
issueごとに集計、そのソースコードを確認、統合してJupyterNotebookで実行、レポートを作成し共有という流れで行いました。
分析内容
・対象データ選択
当社開発の勤怠管理システム「シュキーン」における、学生アルバイト以外の従業員全ての勤怠データを分析対象としました。
従業員について必要なデータを各テーブルから参照してまとめました。
当社従業員には勤務時間の短いアルバイトが含まれます。アルバイトの勤務時間などを分析に含めると統計値に影響がでるため、今回はアルバイトを対象から除外するようクエリを見直しました。
他にも、曜日別集計のため、MySQLでGenerated Columnを用いて勤怠情報テーブルに曜日カラムを追加しました。
・分析期間
シュキーン導入時である2013年から2019年まで、年月ごとに集計を行い、
勤務状況の変化を時系列で確認しました。
・分布状況確認
分布の代表値として、numpyを用いて平均値、中央値を算出しました。
そして、算出した値をmatplotlibでグラフ化しました。
集計した結果の中から残業時間だけ載せます。
青色の線グラフが平均値
オレンジ色の線グラフが中央値になります。
月別残業時間の平均・中央値
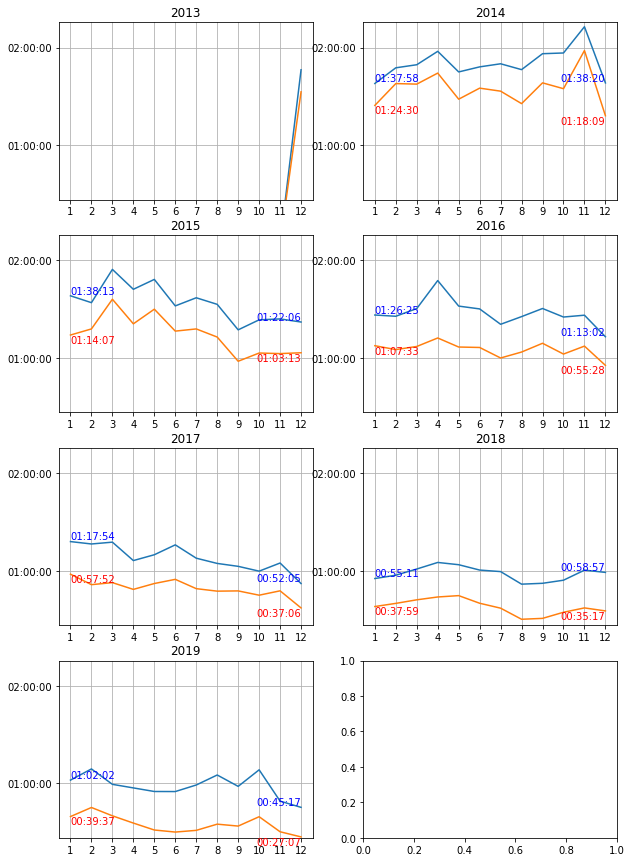
年々残業時間が減少し、この6年間で残業時間の中央値が50%まで減少しました。
また、明らかに多い月が存在しているため、単なるバラつきなのか理由があって残業時間が増えているのか解析する必要があります。
曜日別残業時間の平均・中央値
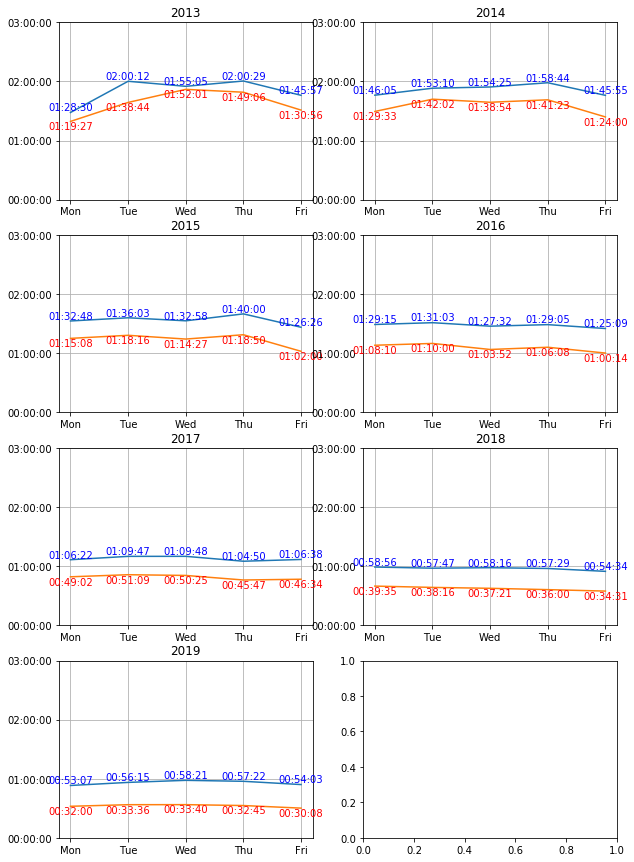
このグラフは残業時間を曜日別で集計してみたグラフです。
若干ですが月曜日と金曜日は減少傾向にあるので因果関係があるのか調査する必要がありそうです。
また、2013年だけ突出したデータがありますので調査する必要があります。
場合によっては外れ値、異常値として判断して集計から取り除かなければいけません。
まとめ
他にも継続年数別で集計したデータなどが大量にありますが、すべて紹介すると記事が何ページあっても足りないので抜粋しました。
この集計を始めた当初は勤怠データのすべてに対して平均や中央値を出していましたが、数値が明らかにおかしいので
・出したい数字に対して集計するデータとして正しいか
・集計の仕方は正しいか
主にこの2点について考え、何度も試行錯誤しました。
今後も定期的に勤怠事情の変化を追っていき、興味深い変化が見つかったらブログで紹介したいと思います。
失敗と反省
初めてデータ分析をリーダーとして管理したため、振り返るともっとうまくやれたと思うところがありました。
・効率よくタスクを振り分けれなかった
原因としては、Pythonとデータ分析についての知見が足りていないということと、それによってこのデータ分析の終着点、目標、目的をしっかりと定めれていなかったことが考えられます。
これらを定めていないために、現状何が必要なのかがはっきりせず、効率のよいタスクを作れずに振り分けもうまくいかなかったと思います。
・チームで分析を進めていく上でのルールを決めていなかった
ここでいうルールというのはAに関する処理はこのファイルで行うようにする、分析結果をグラフに描画してアップロードして共有する流れ、グラフを描画するときに入れてほしい情報などのことです。
最終的にはある程度ルールは定まっていましたが、分析を始めたときは特に決めていなく、アルバイトの人たちも優秀なため各々のやり方で進めていました。そのやり方に問題はないですが、最低限のルールは定めておかないと最後にまとめるときに手間が増えます。また、メンバの作業を確認するときに不明点が出てきたり、新しいメンバが参加する際に手順や現状を説明する際に「今3つのやり方があるんだよね」と言われた新メンバは何をどうすればいいのかわかりません。そのため、ルールをしっかり決めてから動き出したほうが後々の手間が省けると思います。ですが、ルールによる制約を増やすとメンバの個性が出せない状況になることもあります。今回の件で僕はメンバからたくさん刺激を受けましたし、結果的には最初に自由に動いていたのはいい方向に動きました。そのためメンバの個性をつぶさず、メンバ全員が幸せになるルールを定められるように今後心がけていきます。
最後に
近年、インターネットの発展等により展開されているサービスは大量のデータを持つようになりました。今後もこういったデータを分析し経営戦略や社内環境の改善に利用することは増えると思います。そんな中データ分析を携わったことはとても良い経験になりました。
インフィニットループでは学生アルバイトを募集しています。
学生でありながら様々な技術を実践できる環境で一緒に働いてみませんか?
興味があれば採用情報をご覧ください。

