
連載一覧
- 入門 Keras (1) Windows に Tensorflow と Keras をセットアップ
- 入門 Keras (2) パーセプトロンとロジスティック回帰
- 入門 Keras (3) 線形分離と多層パーセプトロン
- 入門 Keras (4) 多クラス分類 – Iris データを学習する
- 入門 Keras (5) 学習済みモデルと Flask で API サービスを作る
第5回は毛色を変えて、学習済みのモデルと Python の Flask フレームワークを使って、簡易的な API サービスを構築します。
まだまだディープラーニングの入り口をちょっと覗いただけですが、せっかくニューラルネットに学習させることが出来るようになりましたので、自分の PC 上の Jupyter Notebook で正解/不正解を確認するだけではなく、おもちゃではありますが実際に動くサービスを作ってみましょう!
仮称 whichiris サービス
第4回に作成した Iris データセットを3種に分類するのと同じものを、今度はAPI サービス whichiris として作ってみましょう。
まずは Anaconda Prompt を起動し、Keras が動く環境に移ったあと whichiris ディレクトリとその下に model と docroot の2つのディレクトリを作成します。
また conda-forge チャネルからの flask のインストールもここで行います。
activate mykeras conda install -c conda-forge flask cd whichiris
(mykeras) C:\Users\n-hatano\whichiris>tree /f
フォルダー パスの一覧
ボリューム シリアル番号は 000000FE C099:5357 です
C:.
├─docroot
│ app.py
│
└─model
training.py
training.py
model ディレクトリに training.py というファイルで学習させるプログラムを作成します。
第4回で使ったコードと基本的には同じですが、checkpointer コールバックを定義して、学習中に損失関数がより小さくなるかモニターしモデルが向上した場合にのみ (save_best_only=True) ファイル名 “iris.h5” でその都度保存するように model.fit に追加しました。
また 学習させる際にはモデルが良くなったかどうか判定するためのテストデータとその正解を vlidation_data というパラメータで渡してあります。
from keras.callbacks import ModelCheckpoint # 損失関数がより小さくなったときだけモデルをファイル保存するコールバック checkpointer = ModelCheckpoint(filepath = "iris.h5", save_best_only=True) # 学習成果をモニターしながら fit させるために、テストデータとその正解を validation_data として付加 model.fit(train_x, train_t, epochs=50, batch_size=10, validation_data=(test_x, test_t), callbacks=[checkpointer])
そして最後のテストにはファイル保存しておいたモデルを model.load_model で読み込み、 ファイルから作成したモデルの方で分類を実行するようにしています。
訓練部分のコード全体は以下になります。
from keras.models import Sequential, load_model
from keras.layers import Dense, Activation
from keras.optimizers import SGD
from keras.utils import np_utils
from keras.callbacks import ModelCheckpoint
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np
'''
データ準備
'''
np.random.seed(0) # 乱数を固定値で初期化し再現性を持たせる
iris = datasets.load_iris()
X = iris.data
T = iris.target
T = np_utils.to_categorical(T) # 数値を、位置に変換 [0,1,2] ==> [ [1,0,0],[0,1,0],[0,0,1] ]
train_x, test_x, train_t, test_t = train_test_split(X, T, train_size=0.8, test_size=0.2) # 訓練とテストで分割
'''
モデル作成
'''
model = Sequential()
model.add(Dense(input_dim=4, units=3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.1))
'''
トレーニング
'''
# 損失関数がより小さくなったときだけモデルをファイル保存するコールバック
checkpointer = ModelCheckpoint(filepath = "iris.h5", save_best_only=True)
# 学習成果をモニターしながら fit させるためにテストデータとその正解を validation_data として付加
model.fit(train_x, train_t, epochs=40, batch_size=10, validation_data=(test_x, test_t), callbacks=[checkpointer])
'''
新たに作ったモデルにファイルから読み込む
'''
app = load_model("iris.h5")
'''
ファイルから作ったモデルで分類する
'''
Y = app.predict_classes(test_x, batch_size=10)
'''
結果検証
'''
_, T_index = np.where(test_t > 0) # to_categorical の逆変換
print()
print('RESULT')
print(Y == T_index)
model ディレクトリで training.py を Anaconda Prompt 上の python で直接動かして動作を確認します。
第4回と同じく最後の RESULT が正しく表示され、iris.h5 ファイルが生成されていれば OK です。
python training.py : : : : : 省略 : : : : : Epoch 38/40 120/120 [==============================] - 0s - loss: 0.1839 - val_loss: 0.1319 Epoch 39/40 120/120 [==============================] - 0s - loss: 0.1820 - val_loss: 0.1361 Epoch 40/40 120/120 [==============================] - 0s - loss: 0.1961 - val_loss: 0.1286 10/30 [=========>....................] - ETA: 0s RESULT [ True True True True True True True True True True True True True True True True True True True True True True True True True True True True True True]
app.py
次に docroot ディレクトリで以下の app.py ファイルを作成します。
Flask フレームワークを使う Web アプリケーションですが、ポイントは
- グローバルのオブジェクトで model を作成し、load_model でファイルから読み込む
global model, graph model = keras.models.load_model("../model/iris.h5") - 次にグローバル・オブジェクトの graph を作成し、get_default_graph でバックエンドの TensorFlow のグラフへの参照を設定しておきます
graph = tf.get_default_graph()
- Flask のルーティングの root() がアプリの本体になりますが
- with graph.as_default() でグローバルで設定した TensorFlow のグラフにこのスレッドでのコンテキストを固定します
- requets.args.get で GET パラメータを入手した後、モデルへの入力を作成します
- 与えるパラメータは4要素の1行のみですが、model.predict_classes は n 行 m 列のデータを想定していますので np.array( [ [ p1, p2, p3, p4 ] ] ) の2次元配列の形式で作成します
詳細は以下のコードの方でご確認ください。
from flask import Flask, request
import numpy as np
import keras.models
import tensorflow as tf
app = Flask(__name__)
# model and backend graph must be created on global
global model, graph
model = keras.models.load_model("../model/iris.h5")
graph = tf.get_default_graph()
@app.route('/', methods=['GET'])
def root():
names = [
'Iris-Setosa セトナ ヒオウギアヤメ',
'Iris-Versicolour バーシクル ブルーフラッグ',
'Iris-Virginica バージニカ'
]
sl = sw = pl = pw = 0.0
sl = request.args.get('sepal_l')
sw = request.args.get('sepal_w')
pl = request.args.get('petal_l')
pw = request.args.get('petal_w')
parm = np.array([[sl, sw, pl, pw]])
with graph.as_default(): # use the global graph
predicted = model.predict_classes(parm)
return names[predicted[0]]
if __name__ == "__main__":
app.run(host='0.0.0.0', port=5000)
ビルトイン Web サーバー起動
python のビルトインの Web サーバーの機能を使って Flask アプリケーションを動かします。 docroot ディレクトリで python app.py コマンドで動きます。終了させるときは CTRL-C を使います。
起動した直後にモデルを読み込んで TensorFlow を使うためのコンパイルが行われますが、GPU 環境でない場合は以下のように SSE や AVX 命令が使える CPU だが使っていない旨のワーニングが出る場合がありますが、そのままで問題ありません。
(mykeras) C:\Users\n-hatano\whichiris\docroot>python app.py Using TensorFlow backend. 2017-12-08 16:29:43.302843: W d:\nwani\l\tensorflow_1497951990344\work\tensorflow-1.1.0\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE instructions, but these are available on your machine and could speed up CPU computations. : : : 2017-12-08 16:29:43.303878: W d:\nwani\l\tensorflow_1497951990344\work\tensorflow-1.1.0\tensorflow\core\platform\cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations. * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
テストしてみる
ブラウザから sepal_w など4つのパラメータを付けながら
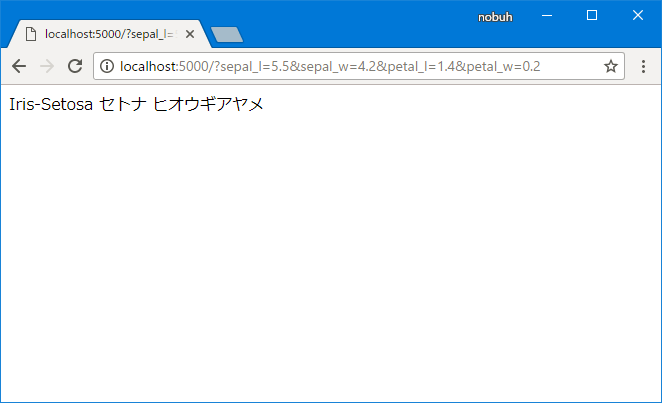
- http://localhost:5000/?sepal_l=5.5&sepal_w=4.2&petal_l=1.4&petal_w=0.2
- http://localhost:5000/?sepal_l=6&sepal_w=2.2&petal_l=4&petal_w=1
- http://localhost:5000/?sepal_l=5.8&sepal_w=2.8&petal_l=5.1&petal_w=2.4
でアクセスしてみましょう。アイリスの名前が出てきました!学習済みのモデルを静的ファイルとしてアプリケーションサーバーに持ち込んで評価に使うことが出来ました!
次に外のマシンから Apache Bench で少し負荷をかけてみます。これは性能を測るためというより、ある程度の同時処理を実行させることで Flask + Tensorflow + Keras で モデルからのpredictが動作しない問題 を正しく回避出来ているかどうか確認するためです。
$ ab -c 16 -n 2000 'http://x.x.x.x:5000/?sepal_l=6&sepal_w=2.2&petal_l=4&petal_w=1' **省略** Document Path: /?sepal_l=6&sepal_w=2.2&petal_l=4&petal_w=1 Document Length: 54 bytes Concurrency Level: 16 Time taken for tests: 0.715 seconds Complete requests: 200 Failed requests: 0 Write errors: 0 Total transferred: 41600 bytes HTML transferred: 10800 bytes Requests per second: 279.88 [#/sec] (mean) Time per request: 57.168 [ms] (mean) Time per request: 3.573 [ms] (mean, across all concurrent requests) Transfer rate: 56.85 [Kbytes/sec] received **省略**
16並列 200 リクエストで 279 リクエスト/秒 で動いていますので、動作的に問題はなさそうです。
まとめ
学習済みの Keras と TensorFlow によるモデルを Flask から使うことに焦点をあてるため、Python のビルトインサーバーを使ったり、Flask のアプリの内容は GET を使ったりなどかなり原始的な内容でしたが、Keras で訓練したモデルをアプリから使う場合の本質を味わって頂けましたら幸いです。
次回 2月6日(火)はまたディープラーニングに話を戻しまして、学習過程の可視化とパラメーターチューニングについてお届けする予定です。ご期待ください!!

